Linux Ubuntu 18.04实战安装大数据Hadoop 3.1.2版本 单节点模式
本文共 1965 字,大约阅读时间需要 6 分钟。
Linux Ubuntu 18.04实战安装大数据Hadoop 3.1.2版本。这里分别选择最新的Ubuntu系统 18.04,以及最新的Hadoop版本3.1.2
Hadoop是开源免费的大数据方案,官方网站,核心的组件都是使用Java开发,也是目前也是最流行的,使用最广泛的大数据解决方案,包括几十个框架和工具。 hadoop有3种模式,我们先使用最简单的模式,来安装实战学习Hadoop。 1)单机模式Local (Standalone) Mode 2)伪分布式Pseudo-Distributed Mode 3)完全分布式Fully-Distributed Mode想要在大数据这个领域汲取养分,让自己壮大成长。分享方向,行动以前先分享下一个大数据交流分享资源群 740041381 ,欢迎想学习,想转行的,进阶中你加入学习。

1、安装JDK
安装开源的JDK,免费,不会引起收费问题。sudo apt install default-jdk

查看安装版本 Java -version

2、安装SSH
sudo apt-get install openssh-server openssh-clientssh-keygen -t rsa -P ""cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys

wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz

4、安装Hadoop
等待下载完毕,解压,然后进行安装配置tar xzvf hadoop-3.1.2.tar.gzmv hadoop-3.1.2 /usr/local/hadoop

查看hadoop是否安装成功
sudo ./bin/hadoop version

5、创建Hadoop账号
为hadoop创建专用账户,并设置为超级用户sudo addgroup hadoopsudo adduser --ingroup hadoop hadoopuser//加为超级用户sudo adduser hadoopuser sudo
6、配置Hadoop环境变量
在.bashrc文件中添加hadoop环境变量,使用下面的命令sudo vim ./.bashrc
然后塞入下面的配置,根据实际路径为准:
export HADOOP_HOME=/home/frankxulei/hadoopexport HADOOP_INSTALL=$HADOOP_HOMEexport HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport YARN_HOME=$HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/nativeexport PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
使生效:
source ./.bashrc7、Hadoop测试例子
我们直接Hadoop自带的示例来测试单机模式是否正常工作。创建input目录,然后拷贝测试文本文件到input中,然后执行hadoop的Job分析结果。 本地创建input文件夹:mkdir ~/input
拷贝测试数据文件到这个文件夹中:
cp /usr/local/hadoop/etc/hadoop/*.xml ~/input
运行下面的命令,mapreduce分析出出a开头的单词频率
bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar grep ./input/ ./output 'a[a-z.]+'
等待漫长的分析计算过程结束,你会看到hadoop不断输出日志信息,读取、清洗、统计结果
cat ~/output/*
结果信息安装不同的单词,频率倒序输出结果,如图所示,表示Hadoop分析过程成功执行
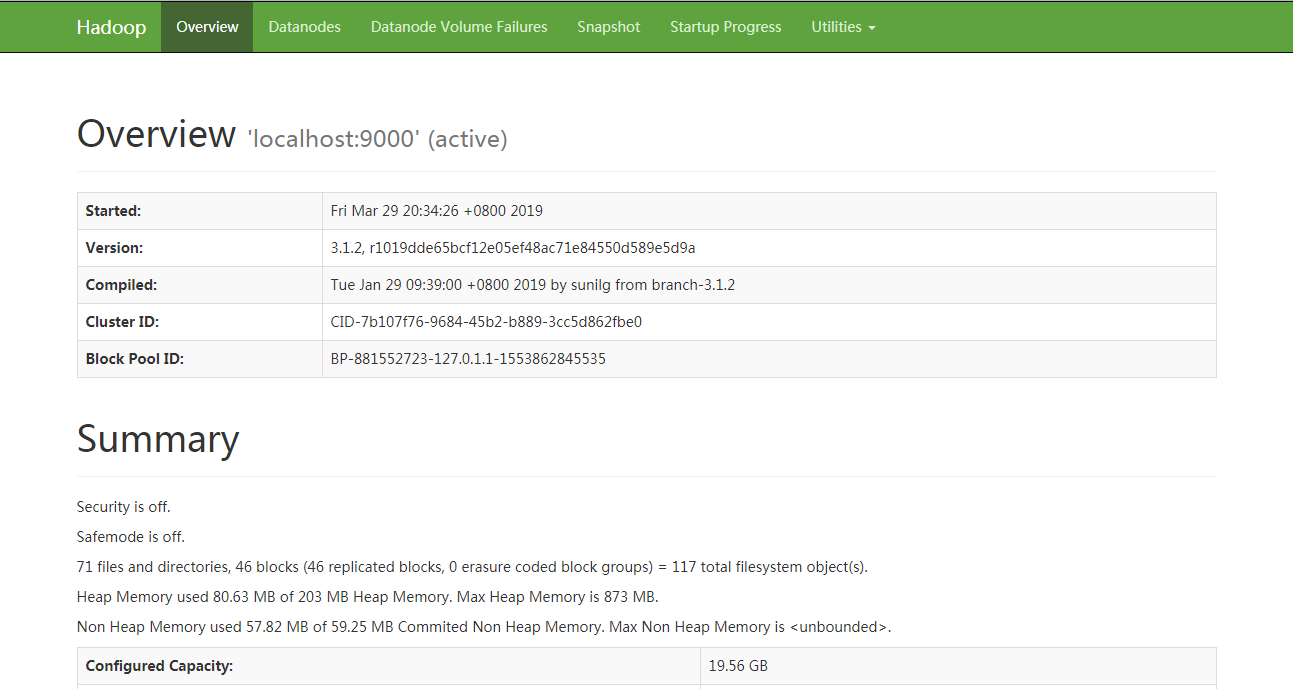 启动Hadoop可以在地址,查看Hadoop服务运行状态信息
启动Hadoop可以在地址,查看Hadoop服务运行状态信息 
阿里巴巴Java群超过4500人 转载地址:http://zoclf.baihongyu.com/
你可能感兴趣的文章
(PAT 1019) General Palindromic Number (进制转换)
查看>>
(PAT 1073) Scientific Notation (字符串模拟题)
查看>>
(PAT 1080) Graduate Admission (排序)
查看>>
Play on Words UVA - 10129 (欧拉路径)
查看>>
mininet+floodlight搭建sdn环境并创建简答topo
查看>>
【UML】《Theach yourself uml in 24hours》——hour2&hour3
查看>>
【linux】nohup和&的作用
查看>>
【UML】《Theach yourself uml in 24hours》——hour4
查看>>
Set、WeakSet、Map以及WeakMap结构基本知识点
查看>>
【NLP学习笔记】(一)Gensim基本使用方法
查看>>
【NLP学习笔记】(二)gensim使用之Topics and Transformations
查看>>
【深度学习】LSTM的架构及公式
查看>>
【深度学习】GRU的结构图及公式
查看>>
【python】re模块常用方法
查看>>
【JavaScript】call()和apply()方法
查看>>
【JavaScript】箭头函数与普通函数的区别
查看>>
前端面试题
查看>>
【JavaScript】常用方法记录
查看>>
C++ 数据存储类型
查看>>
39. Combination Sum
查看>>